
Introduction
Retrieval-Augmented Generation (RAG) is rapidly becoming the foundation of modern AI applications, enabling systems to combine the reasoning power of large language models with real-time, external knowledge. From intelligent search and customer support bots to enterprise copilots, RAG allows developers to build applications that are more accurate, contextual, and adaptable.
However, building a RAG system is only the first step. The real challenge lies in evaluating whether the system is actually reliable. Unlike traditional AI models, RAG systems introduce multiple points of failure, retrieving irrelevant information, missing critical context, or generating responses that are not fully grounded in the source data. Without a proper evaluation framework, these issues can quietly degrade performance and erode user trust.
This is where a structured approach to evaluation becomes essential. In this guide, we will explore how to evaluate RAG systems using the RAG Triad Context Relevance, Faithfulness, and Answer Relevance, along with key metrics, techniques, and best practices that help developers build accurate, trustworthy, and production-ready AI systems.
What is a RAG System?
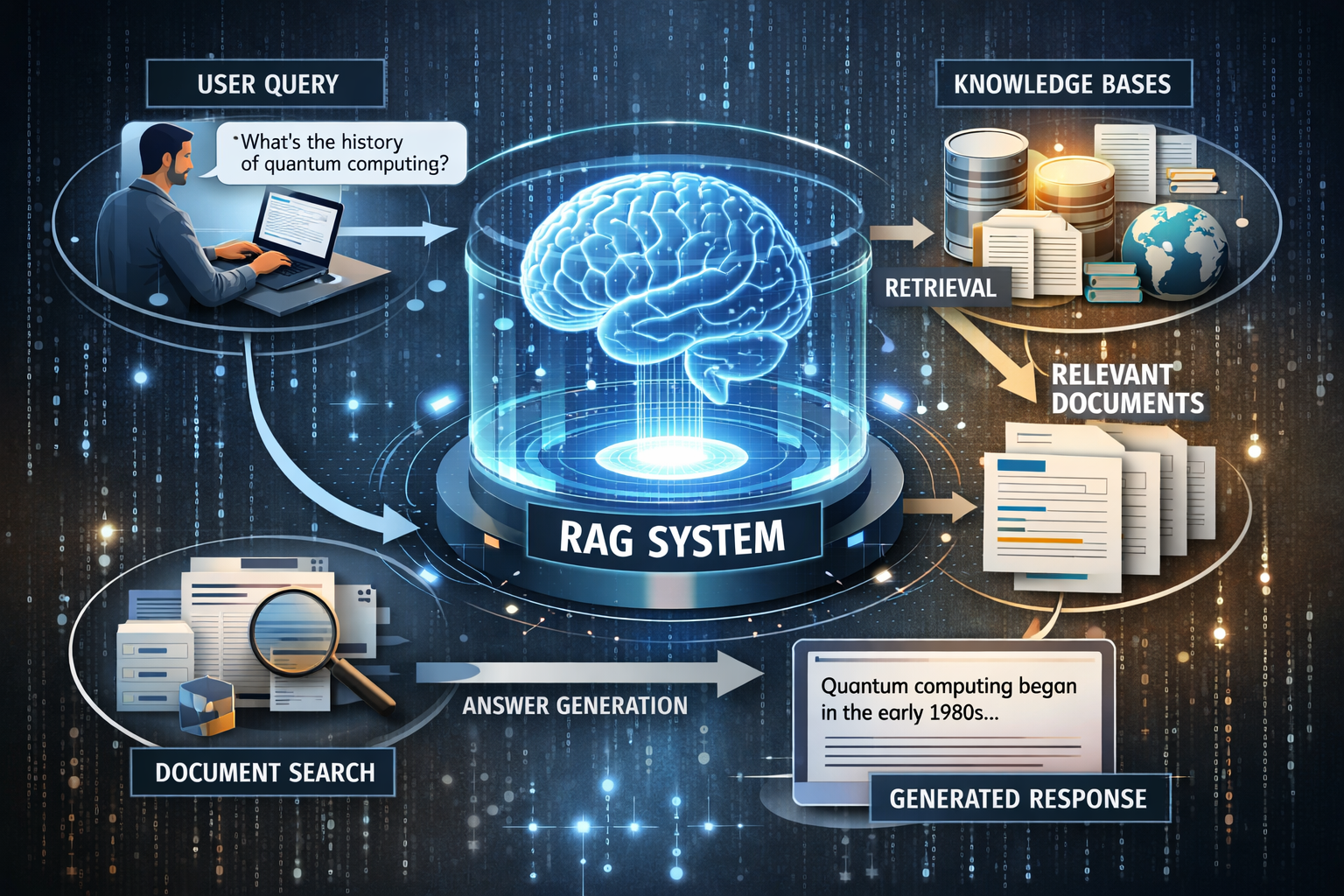
A Retrieval-Augmented Generation (RAG) system is an architecture that enhances a language model by connecting it to an external knowledge source. Instead of relying solely on what the model learned during training, the system first retrieves relevant documents from a database (such as vector stores, APIs, or internal knowledge bases) and then uses those documents to generate a response.
This approach fundamentally changes how AI behaves. Instead of guessing or hallucinating answers, the model is guided by real, verifiable information. For developers, this means building systems that are more controllable, auditable, and adaptable, especially in environments where information changes frequently or must be accurate.
Why is RAG Used?
RAG is widely used because it addresses one of the most critical limitations of traditional LLMs: their inability to stay current and consistently factual. Since most models are trained on static datasets, they cannot inherently access recent updates or proprietary information. RAG solves this by enabling dynamic knowledge injection at runtime.
In practical terms, this allows developers to build applications such as customer support bots that reference live documentation, enterprise assistants that query internal databases, or marketplaces that surface accurate listing details. It also reduces the need for costly model retraining, making it a more scalable and maintainable approach for real-world systems.
Key RAG Evaluation Metrics
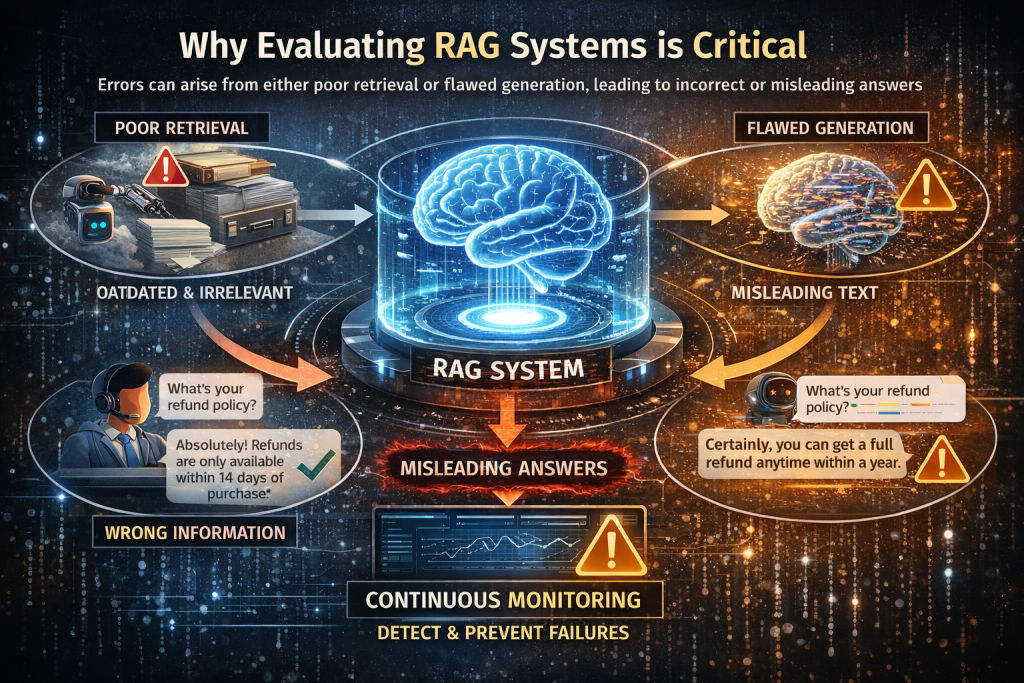
Evaluation is critical because RAG systems introduce multiple points of failure across both retrieval and generation. Unlike standalone LLMs, where errors mainly come from generation, RAG systems depend on fetching the right context and using it correctly. If either step fails, the final answer becomes unreliable.
For example, in a customer support chatbot, if a user asks about a refund policy and the system retrieves outdated or irrelevant documents, the model may generate a confident but incorrect answer. Similarly, even with the correct documents, the model might misinterpret the context and produce a misleading response. In both cases, the system appears correct but actually fails.
These failures are often subtle and hard to detect, which makes evaluation essential. Without continuous monitoring, issues like poor retrieval, hallucinations, or irrelevant answers can go unnoticed and degrade performance over time. That’s why RAG evaluation should be treated as an ongoing process, ensuring the system remains accurate, trustworthy, and effective in real-world use.
1. Retrieval Accuracy (Context Relevance):
Retrieval accuracy measures how effectively the system fetches relevant documents in response to a query, forming the foundation of any RAG system. Since the generator depends entirely on the retrieved context, even small retrieval errors can cascade into incorrect outputs. In practice, retrieval quality is heavily influenced by factors such as embedding model performance, chunking strategy, and indexing methods used in vector databases. For example, overly large document chunks may dilute relevance, while very small chunks may lose context.
A common real-world failure occurs when a user searches for “subscription cancellation policy” but receives pricing-related documents due to weak semantic matching. Developers typically evaluate retrieval using metrics like Precision@K, Recall@K, MRR, and NDCG, but it’s equally important to manually inspect retrieved results and align them with user intent. Improving retrieval often involves fine-tuning embeddings, optimizing chunk sizes, and implementing re-ranking mechanisms to prioritize the most relevant content.
2. Answer Faithfulness (Groundedness):
Answer faithfulness evaluates whether the generated response is strictly grounded in the retrieved context, ensuring that no unsupported or fabricated information is introduced. This is critical for reducing hallucinations, which remain one of the biggest challenges in AI systems. Even when relevant documents are retrieved, models may still generate incorrect details due to overgeneralization or poorly structured prompts. For instance, if a document states “refunds are allowed within 30 days,” but the model responds with “refunds are allowed anytime,” it indicates a breakdown in grounding.
Developers assess faithfulness by verifying whether each claim in the response can be traced back to the source documents. Advanced evaluation techniques include LLM-based verification, claim extraction, and citation matching, which help automate this process at scale. Ensuring strong faithfulness builds trust and makes the system suitable for high-stakes applications.
3. Answer Relevance:
Answer relevance measures how well the generated response addresses the user’s actual query, focusing on usefulness rather than just correctness. A response can be factually accurate yet fail if it does not directly solve the user’s problem. In production systems, irrelevant answers often arise from poorly designed prompts, excessive or unfocused context, or weak query understanding. For example, if a user asks “How do I update my billing details?” and receives a generic explanation of account settings, the response lacks actionable value.
Developers evaluate this using semantic similarity scoring, user feedback signals, and human review, ensuring that responses align closely with user intent. Improving answer relevance often involves refining prompts, structuring context more clearly, and incorporating query rewriting techniques to better capture user intent.
4. Context Utilization:
Context utilization evaluates whether the model is effectively using the retrieved documents when generating responses. In many cases, even when the correct context is retrieved, the model may ignore key details or rely on its internal knowledge instead. This often happens due to token limits, poor prompt structure, or lack of explicit instructions to prioritize retrieved content. For example, if critical information exists in the retrieved documents but is missing from the final answer, it indicates weak context utilization.
Developers can improve this by restructuring prompts (e.g., emphasizing “use only the provided context”), applying context compression or summarization techniques, and re-ranking documents to surface the most important information first. Strong context utilization ensures that the system fully leverages retrieved knowledge rather than defaulting to generic responses.

5. Latency and System Performance:
Latency is a crucial factor in real-world RAG applications because it directly impacts user experience and system scalability. Since RAG pipelines involve multiple steps, query embedding, vector search, and response generation, they are inherently more complex and slower than standalone models. High latency can lead to user frustration, especially in interactive applications like chatbots or search assistants. Developers must monitor each stage of the pipeline and identify bottlenecks, such as slow vector database queries or large context payloads.
Optimization strategies include caching frequent queries, reducing context size, using faster embedding models, and parallelizing retrieval and generation steps. Balancing latency with accuracy is key to delivering a system that is both efficient and reliable.
| Metric | What It Measures | Why It Matters |
|---|---|---|
| Precision@K | The proportion of relevant documents among the top K retrieved results | Ensures the system retrieves high-quality, relevant context with minimal noise |
| Recall@K | The proportion of all relevant documents that were successfully retrieved | Ensures the system does not miss critical information needed to answer the query completely |
| Faithfulness | Whether the generated answer is fully supported by the retrieved context | Prevents hallucinations and ensures responses are grounded, trustworthy, and verifiable |
6. Robustness and Edge Case Handling:
Robustness measures how well the system performs under diverse and unpredictable inputs, reflecting real-world user behavior. Users often submit queries with typos, incomplete context, slang, or multi-step reasoning requirements. A robust RAG system should handle these variations without breaking or producing misleading results. For example, a vague query like “What about refunds?” should still trigger the system to infer context and provide a meaningful answer.
Developers improve robustness by testing against adversarial queries, long-tail scenarios, and query variations, ensuring the system performs consistently across different inputs. Techniques such as query rewriting, fallback mechanisms, and hybrid search (keyword + semantic) can further enhance system resilience.
RAG Evaluation Techniques
Human Evaluation:
Human evaluation remains one of the most reliable methods for assessing RAG systems, particularly in early stages or high-risk applications. While automated metrics provide scalability, they often fail to capture nuances such as tone, clarity, and contextual appropriateness. Human reviewers can identify subtle issues like partially correct answers, misleading phrasing, or gaps in reasoning that automated systems may overlook. For example, a response may be technically correct but confusing or poorly structured for end users. Although human evaluation is time-intensive, it provides high-quality qualitative insights that are essential for refining system behavior and validating automated evaluation methods.
LLM-as-a-Judge:
LLM-as-a-judge is an increasingly popular technique where one language model evaluates the output of another based on predefined criteria such as relevance, correctness, and faithfulness. This approach enables scalable and automated evaluation, making it suitable for large datasets and continuous testing. For example, a model can assign scores (e.g., 1–5) to responses based on how well they align with the query and retrieved context. However, the effectiveness of this method depends heavily on well-designed evaluation prompts and clear scoring criteria. When implemented correctly, LLM-based evaluation acts as a continuous feedback mechanism, helping developers quickly identify weaknesses and iterate on improvements.
Benchmark Datasets:
Benchmark datasets provide a structured and repeatable way to evaluate RAG systems using predefined queries, reference answers, and expected supporting documents. These datasets serve as a baseline for measuring system performance and tracking improvements over time. For developers, creating domain-specific benchmarks is particularly valuable, as it ensures evaluation aligns with real-world use cases. For example, a marketplace platform might include queries related to product listings, transactions, and policies. High-quality benchmarks enable consistent testing and make it easier to compare different system configurations or model versions.

Synthetic Test Data Generation:
Synthetic test data generation involves using LLMs to create additional queries and scenarios for evaluation, helping expand dataset coverage. This is particularly useful when real user data is limited or when testing edge cases that rarely occur in practice. For example, developers can generate variations of queries, simulate ambiguous inputs, or create complex multi-step questions to stress-test the system. This approach enables faster iteration and ensures that the system is tested across a broader range of scenarios, ultimately improving robustness and reliability.
Popular RAG Evaluation Frameworks
Ragas
Ragas is a widely adopted framework designed specifically for RAG evaluation. Its key strength lies in providing reference-free metrics, meaning it can evaluate outputs without requiring a predefined ground truth. It measures aspects like faithfulness, answer relevance, and context relevance, helping developers quickly identify issues such as hallucinations or weak retrieval. Ragas is lightweight, easy to integrate, and works well with frameworks like LangChain and LlamaIndex, making it ideal for rapid experimentation and early-stage evaluation.
DeepEval
DeepEval is a flexible framework focused on custom evaluation and testing workflows. Developers can define their own evaluation criteria, making it highly adaptable for domain-specific applications. It supports hallucination detection, correctness checks, and rule-based validations, and allows teams to write evaluation cases similar to unit tests. This makes it particularly useful for integrating into CI/CD pipelines, ensuring that every update to the RAG system is automatically tested and validated.
TruLens
TruLens emphasizes explainability and debugging by providing detailed insights into how each component of a RAG pipeline contributes to the final response. It enables developers to trace which documents were retrieved, how they were ranked, and how much they influenced the generated answer. This level of transparency helps identify issues like poor context usage or incorrect ranking, making TruLens a powerful tool for fine-tuning and optimizing system behavior.
Arize Phoenix
Arize Phoenix is built for observability and monitoring, helping teams track RAG system performance in real-world environments. It provides tools to analyze embeddings, monitor retrieval quality, and trace responses across sessions. Developers can detect patterns such as performance degradation, inconsistent outputs, or retrieval failures over time. This makes Phoenix especially valuable for production systems, where continuous monitoring is essential for maintaining reliability and user trust.
Vertex AI Evaluators
Vertex AI Evaluators offer a scalable, cloud-native solution for evaluating RAG systems within Google Cloud. Developers can define custom metrics, compare outputs against ground truth data, and run large-scale evaluations across different model versions. Its seamless integration with other cloud services makes it ideal for teams building enterprise-grade AI applications, where automation, scalability, and governance are key requirements.
Final Thoughts
By applying the RAG Triad, using the right metrics, and leveraging evaluation frameworks, teams can build systems that are accurate, reliable, and production-ready. Ultimately, evaluation is what turns a basic RAG pipeline into a trustworthy real-world AI solution.
FAQ's
1. What is the RAG Triad and why is it important?
The RAG Triad consists of Context Relevance, Faithfulness, and Answer Relevance. It provides a structured way to evaluate RAG systems by checking whether the system retrieves the right data, generates grounded responses, and answers user queries effectively.
2. What is the biggest challenge in evaluating RAG systems?
The main challenge is that RAG systems have multiple failure points. Issues can arise from poor retrieval, hallucinations in generation, or irrelevant answers, making it harder to identify the exact root cause without a proper framework.
3. How can developers reduce hallucinations in RAG systems?
Developers can reduce hallucinations by improving retrieval quality, enforcing grounding through prompts, and evaluating faithfulness to ensure all responses are supported by retrieved context.
4. What metrics are most important for RAG evaluation?
Key metrics include Precision@K, Recall@K, MRR, NDCG for retrieval, and faithfulness, hallucination rate, and answer relevance for generation and end-to-end evaluation.
5. Which tools are commonly used for RAG evaluation?
Popular tools include Ragas, DeepEval, TruLens, Arize Phoenix, and Vertex AI Evaluators, each helping with different aspects like automated scoring, debugging, monitoring, and large-scale evaluation.